by Jayanth Kumar
So, you have built your enterprise application as loosely coupled micro-services, even made them serverless after reading my old article — Serverless Microservices but after attending a few cool tech conferences and coming across the term — event-driven or event-sourcing architectures, you start wondering whether you have made the right architectural decisions. You revisit your domain problem, relook at the business requirements, and then, comes the problem:
So, you have built your application architecture on top of Entity Relationship Model or Object Model or Attribute Value Model, using those models to capture the application state for your business problem.
Then, the audit department comes in, asking an explanation for how a particular object evolved to a particular value or may request you to revert or time-travel back to a specific state of the object in the business context. In simple words, they don’t care where the application state is now as that may have become corrupt but want to drill down to the root cause of that state corruption by figuring out how it got there by which events, as well as revert back to the last valid state of the business object.
Also, as you add more and more objects and services and glue them together, you start worrying about the scalability of any audit logs, you would create to capture the evolution of the objects in the application state.
You look at the problem from the first principles and start by understanding that the business logic can be modelled as event-driven state machines:
State Machine — A state machine is a mathematical abstraction used to design algorithms based on behaviour model. A state machine reads a set of inputs and changes to a different state based on those inputs.
State — A state is a description of the status of a system waiting to execute a transition.
Transition — A transition is a change from one state to another. A transition is a set of actions to execute when a condition is fulfilled or an event received.
Event — The entity that drives the state changes.
Event-driven State Machine — A state machine is event-driven, if the transition from one state to another is triggered by an event or a message (not based on consuming/parsing characters or based on conditions).
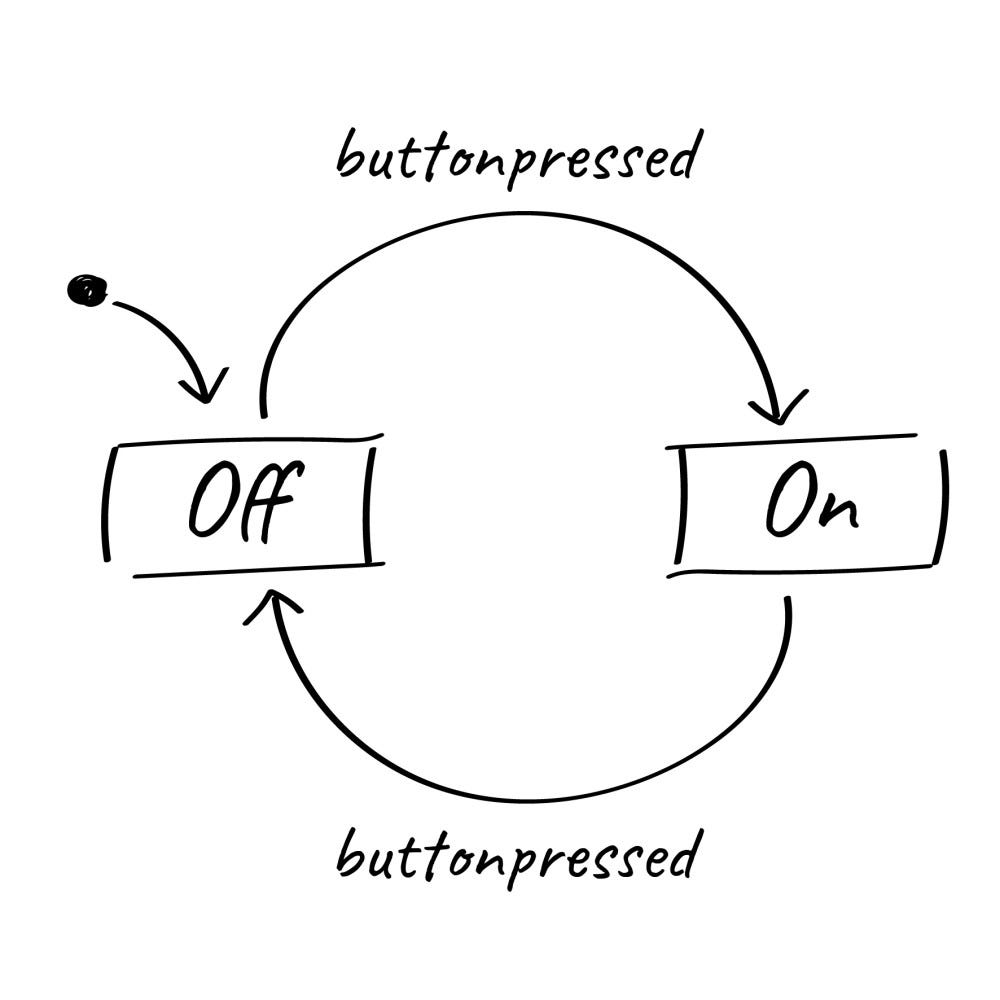
Here is a sample example of an event-driven state machine for a button application, having two states of On and Off and one action of buttonPressed:
Event Driven Systems — Event Driven Architecture is about components communicating via publishing events rather than making (e.g.) RPC/CRUD calls against each other or manipulating shared state. It’s a communication strategy (albeit one which often relies on messages being persisted for fairly long periods until they are consumed).
Paradigm 1 — State oriented Object Model or Attribute Value Model : The implementation of event driven system can be done by capturing only the current state of the system. This naturally, is based on model state oriented persistence, that only keeps the latest version of the entity state. State is stored as dictionary or record of attribute values and the attributes are first-class citizens, which are only modified by allowed encapsulated methods as event actions.
public class button {
boolean state;
public void buttonPressed(){
state = !state;
}
public void setState(boolean state){
this.state = state;
}
public boolean getState(){
return state;
}
}
For example, the state of the button application, which was initially only stored as an attribute value of On or Off encapsulated along with the modifier action of buttonPressed as the method in the Entity Relationship Model or Object Model or Attribute Value Model. The system is still event-driven as it operates on the events but the events are not the first-class citizens of this system but rather, the current attribute value or state of the entity button, whether it is on or off is the first class citizen. The event or encapsulated method of buttonPressed is not stored but just, applied eagerly to update the current state and thus, can’t be replayed or time-travelled.
Consider another example of a shopping cart service, where the cart is represented as a record in a carts table and a cart-items table represents rows that say “2 bananas in cart 101 with price $1 a piece” in relational model. To add items to the cart, we insert (or update if it’s just a quantity change) rows to the cart-items table. When the cart is checked out, we publish a representation of the cart in json or other serialized formart and its contents so the shipping service has what’s in the cart and we set carts.checked_out to TRUE.
That’s a perfectly sane Event Driven Architecture. The cart service communicates that there’s a checked out cart to the shipping service. However, it’s not event-sourced, i.e. we can’t reconstruct the database tables from the events as we are not tracking the events.
Paradigm 2 — Event Sourcing : The implementation of event driven system can also be done by capturing only the events manifested into the system. This naturally, is based on event-sourced (using event journal) persistence, where each state/attribute mutation is stored as a separate record called as an event. Events are first-class citizens in the persistence and states and attributes are side-effects of events. We store the events, and lazily apply it to derive the state or attributes in the query resolver. Events can also be replayed or time-travelled.
enum event {
BUTTON_PRESSED
}
public class event_sourced_button {
List < event > buttonEvents = new ArrayList < event > ();
public void buttonPressed() {
buttonEvents.add(event.BUTTON_PRESSED);
}
private boolean applyEvent(event e, boolean state) {
if (e == event.BUTTON_PRESSED)
state = !state;
return state;
}
public boolean getState(boolean initialState) {
boolean state = initialState;
for (event e: buttonEvents)
state = applyEvent(e, state);
return state;
}
}
For example, the event sourced implementation of the button application will not store the state of the button but rather, will store the events of buttonPressed on the button and will apply those events one by one to derive the current state. The system is event-driven as well as event-sourced as it operates on the events by making the events as the first-class citizens of this system, only storing them and then, deriving the current attribute value or state of the entity button, whether it is on or off from the event list. The events are just, applied lazily to evaluate the current state, given the initial state and thus, can be replayed or time-travelled upto certain time or events.
Similarly, the previous example of shopping cart service could also be made event sourced. It stores events in an event store (which could be a datastore designed for the needs of event sourcing or could be relational database or non-relational database being used in a particular way (e.g. an events table)). The following sequence of events for cart 101 might be written to the event store:
That last event (along with the fact that it’s for cart 101, which is metadata associated with the event) can be used to derive an event for publishing. One key thing to note is that there’s nothing else being written to the database but these events.
Since, event sourcing mandates keeping a persistence journal log of the events, which forms the single source of truth to derive the application state, this in-turn provides a number of facilities that can be built on top of the event log:
The Event Sourcing pattern captures the application state transition or the data mutations by storing the sequence of events (each representing that data or state mutation), each of which is recorded in an immutable append-only store. That immutable append-only store acts as a single source of truth about the operations on the application state and data as well as, the event store typically publishes these events so that consumers can be notified and can handle them, if needed. Consumers could, for example, initiate tasks that apply the operations in the events to other systems, or perform any other associated action that’s required to complete the operation, thus decoupling the application from the subscribed systems.
An Event Sourced persistence will model the entities as Event Streams and keep an immutable journal of these event streams. When the entity state or attribute mutates, a new event is produced and saved. When the entity state needs to be restored, all the events for that entity are read and each event is applied to change the state, reaching the correct final state of the entity. Note that, State here, is the pure function application of the event stream on the entity.
Here is how a sample EntityStoreAdaptor on top of Event Store persistence for Event Sourcing will look like:
public class EntityStoreAdapter {
EventDatabase db;
Serializer serializer;
//Command Applier Eager
public void Save < T > (T entity) where T: Entity {
var changes = entity.changes;
if (changes.IsEmpty()) return; // nothing to do
var dbEvents = new List < DbEvent > ();
foreach(var event in changes) {
var serializedEvent = serializer.Serialize(event);
dbEvents.Add(
data: new DbEvent(serializedEvent),
type: entity.GetTypeName();
);
}
var streamName = EntityStreamName.For(entity);
db.AppendEvents(streamName, dbEvents);
}
//Query Resolver Lazy
public T Load < T > (string id) where T: Entity {
var streamName = EntityStreamName.For(entity);
var dbEvents = db.ReadEvents(streamName);
if (dbEvents.IsEmpty()) return default (T); // no events
var entity = new T();
foreach(var event in dbEvents) {
entity.When(event);
}
return entity;
}
}
In end-user facing applications, the current state of the application needs to be derived on-demand and that is derived from the materialization of the events as actions on top of the entity states. This can also, be done using a scheduled job so that the state of the entity can be stored for querying and presentation.
For example, a system can maintain a materialized view of all customer orders that’s used to populate parts of the UI, say aggregated view. As the application adds new orders, adds or removes items on the order, and adds shipping information, the events that describe these changes can be handled and used to update the materialized view.
Event sourcing is commonly combined with the CQRS pattern, an architectural style that separates reads from writes. In CQRS architecture, data from write database streams to a read database and gets materialized on which queries run. Since, Read/Write layers are separate, the system remains eventually consistent but scales to heavy reads and writes.
Change data events use the underlying database transaction log as the source of truth. The event is based on the database that the transaction log belongs to, rather than the original application and the event is available for as long as the events are persisted (not immutable) based on a mutable database, which means tighter coupling to the database data model. The CDC captures the effect of the event in terms of create, update or delete, for example, the button was update to off state.
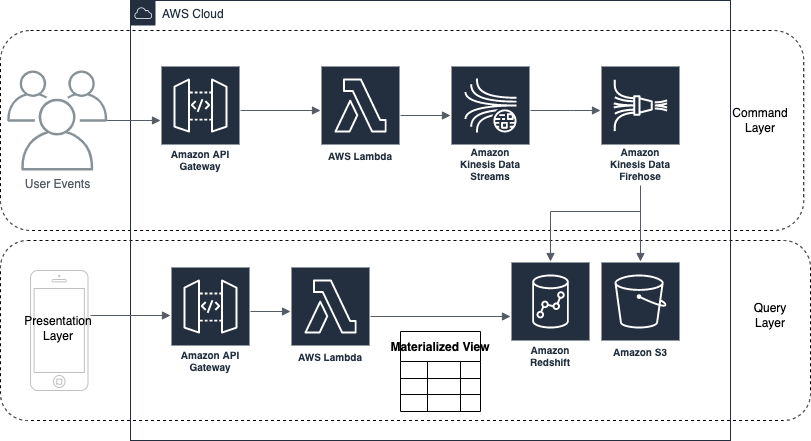
Event Sourcing can be realized end-to-end as let’s say on AWS :
So, you have now understood the event driven systems architecture and dived deep into event sourcing to implement such system. However, the use-cases of event sourcing systems needs to taken into consideration before going ahead with the implementation of such complex system for event driven architecture. The event sourcing should be used, when intent, purpose, or reason in the data needs to be captured as recorded events that occur, and be able to replay them to restore the state of a system, roll back changes, or keep a history and audit log, i.e. events emerge as natural first-class functional feature of the system and the system can accept eventual consistency for the data entity models as its non-functional side-effect.
Solve the problem once, use the solution everywhere!
Architecting Event driven Systems the right way was originally published in Technopreneurial Treatises on Medium, where people are continuing the conversation by highlighting and responding to this story.
tags: